Aiming to further improve how artificial intelligence curates biometric data in order to enhance security in facial recognition systems, a new Datathon has prepared a repository of facial recognition datasets. This repository enables companies and developers to create applications and systems that are fully respectful of the user.
Facial recognition technology has experienced significant take up across a number of sectors, such as security, commerce, finance, and healthcare. However, with its growing prevalence, concerns have emerged regarding privacy infringement and the potential for discrimination. To address these pressing issues, the Digital Future Society, a joint initiative by the Ministry of State for Digitization and Artificial Intelligence, Red.es, and Mobile World Capital Barcelona, recently collaborated with key stakeholders to conduct a Datathon exercise, specifically designed to tackle these critical concerns head-on. In this context, we would like to express our sincere gratitude and recognition to all the participants of the Datathon. Their valuable participation and contributions were essential elements for the success of this event. We deeply appreciate the work and dedication demonstrated by each participant, whose names have been included in the final report of the Datathon.
The exercise focused on the retrieval and classification of open data for facial recognition, while also analysing the compliance of existing facial recognition systems, all within the new framework of European legislation.
During the Datathon, a total of 56 datasets were identified, which were divided into two categories: “VERIFIED” and “UNVERIFIED”. The list of “VERIFIED” datasets includes those in which at least one of the required ethical and security factors could be verified.
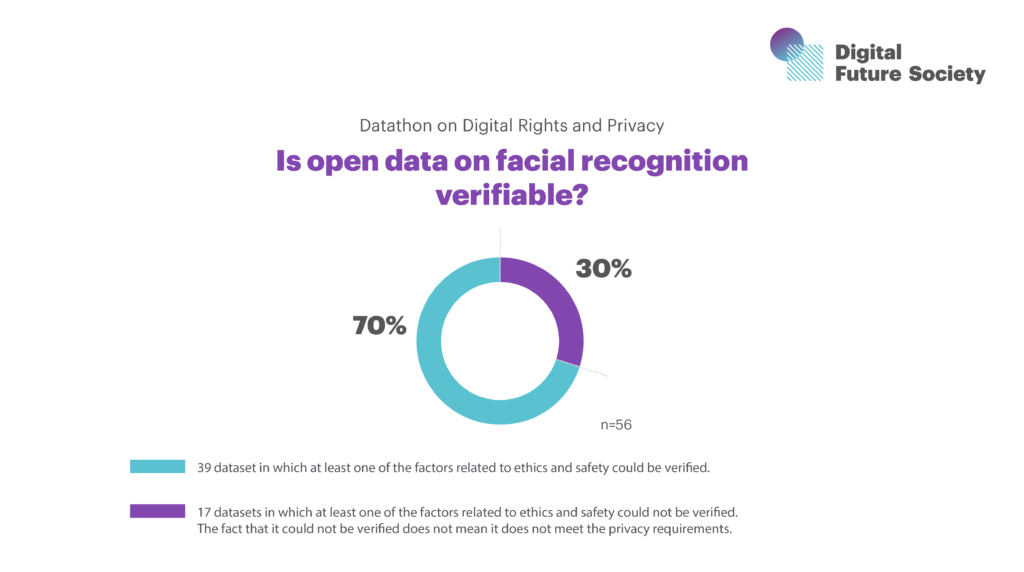 Within the “VERIFIED” list, which consists of a total of 39 datasets, there are 13 datasets that are completely open, while the remaining 26 require some kind of registration to be downloaded.
Within the “VERIFIED” list, which consists of a total of 39 datasets, there are 13 datasets that are completely open, while the remaining 26 require some kind of registration to be downloaded.

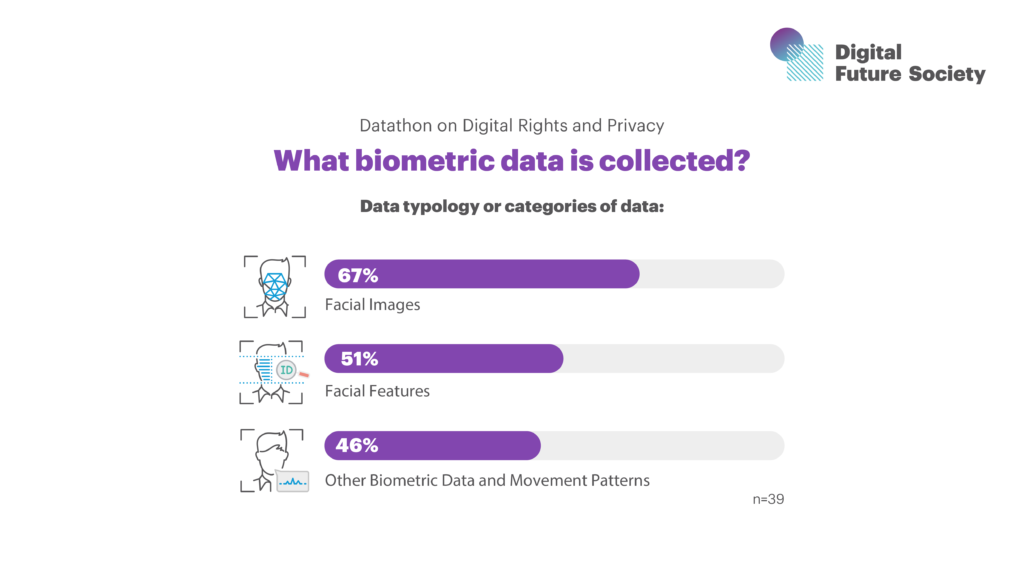
When classifying the data present in the datasets into the four categories that were taken into consideration during the datathon, we find that out of the 39 verified datasets, 67% include facial images, 51% contain facial features, and 46% contain other biometric data and motion patterns.
Furthermore, upon closer examination of the level of compliance of these datasets in terms of verified ethical and legal aspects, we find that gender equality and legitimate purpose are the aspects that are most frequently fulfilled, each present in 59% of the datasets. Anonymisation is successful in 51% of the datasets, while transparency is successful in 46% of the datasets. On the other hand, impact assessment is the least mentioned aspect, being explicitly mentioned in only 8% of the datasets.
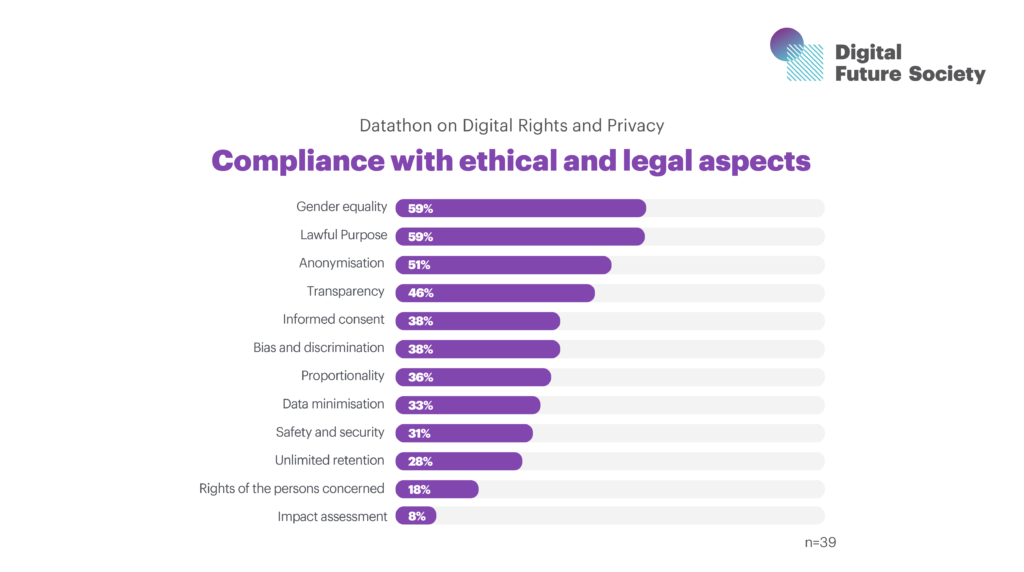
The average compliance rate of these aspects, after analysing 39 verified datasets, stands at 37.18%, suggesting that there is still much work to be done to improve the ethics and legality in data creation and usage.
In conclusion, access to and use of open, ethical, and legal datasets are fundamental if we want to ensure responsible progress in the field of digital identity and digital rights. It is essential to foster the creation of such datasets and promote collaborations among different entities to ensure their quality and compliance with ethical and legal aspects.